БД можно масштабировать двумя способами: вертикально и горизонтально.
При вертикальном масштабировании меняется количество ядер и объём жёсткого диска на хосте, где работает база данных. Например, вы можете поменять тип хоста с s2.medium (8 ядер и 32 ГБ оперативной памяти) на s2.x4large (40 ядер и 160 ГБ оперативной памяти) и увеличить объём диска на 50 ГБ. Такая операция занимает всего несколько минут. У этого способа, однако, есть предел: очередное увеличение станет или слишком дорогим, или технически невозможным.
При горизонтальном масштабировании меняется число хостов, между которыми распределена нагрузка на БД. Такой способ поддерживают не все СУБД, но если эта возможность есть, то с технической точки зрения уже неважно, сколько хостов вы добавляете.
Производительность и объём диска одного хоста бывают небольшими, но каждый хост обрабатывает лишь часть общей нагрузки и хранит часть общих данных. Такая система может быть эффективнее, чем один большой и мощный сервер.
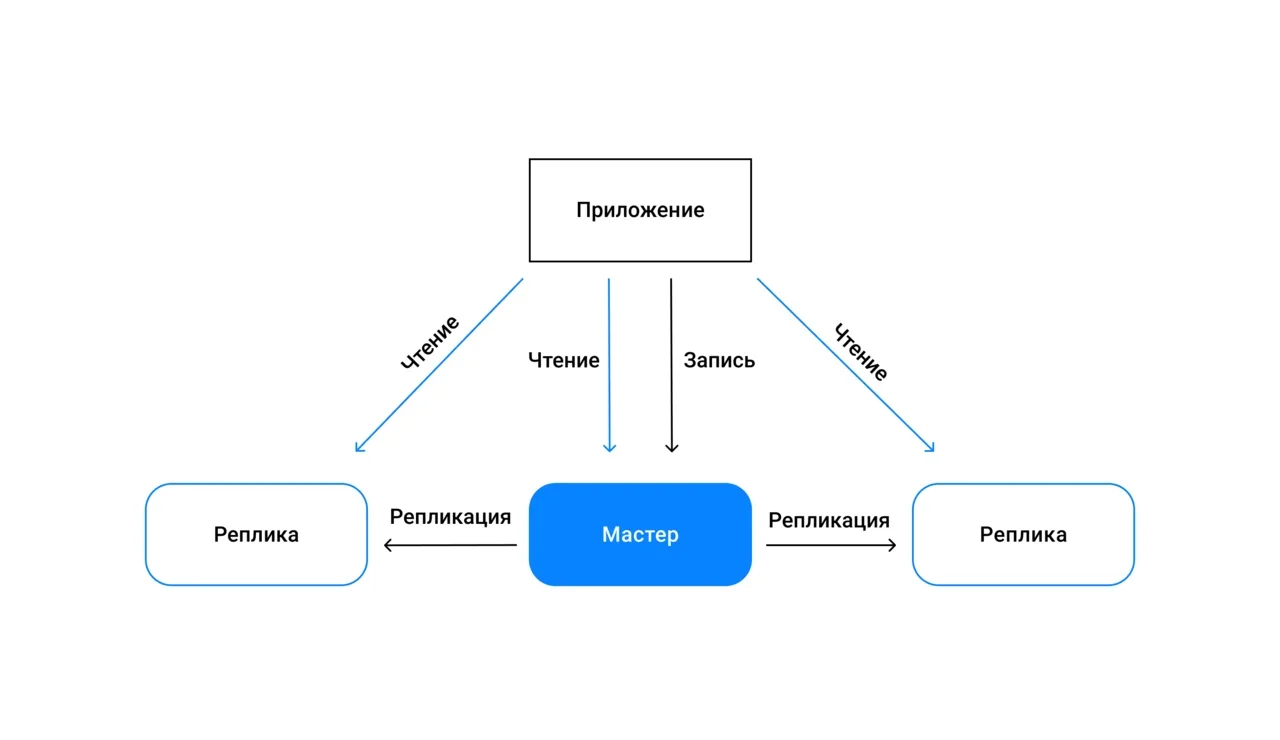
Сервисы управляемых БД помогут вам без особых усилий улучшить доступность приложения или сайта. Когда вы разворачиваете БД на одном из хостов кластера, сервис автоматически её реплицирует: создает копии (реплики) основной базы (мастера) на остальных хостах и синхронизирует данные между мастером и репликами.
ClickHouse
ClickHouse — это столбцовая СУБД для онлайн-обработки аналитических запросов.
Данные в ClickHouse организованы в таблицах и жестко структурированы. Но в отличие от реляционных БД, которые хранят на диске рядом друг с другом значения всех свойств одного объекта (строку таблицы), в столбцовых СУБД рядом хранятся значения одного свойства всех объектов (столбец).
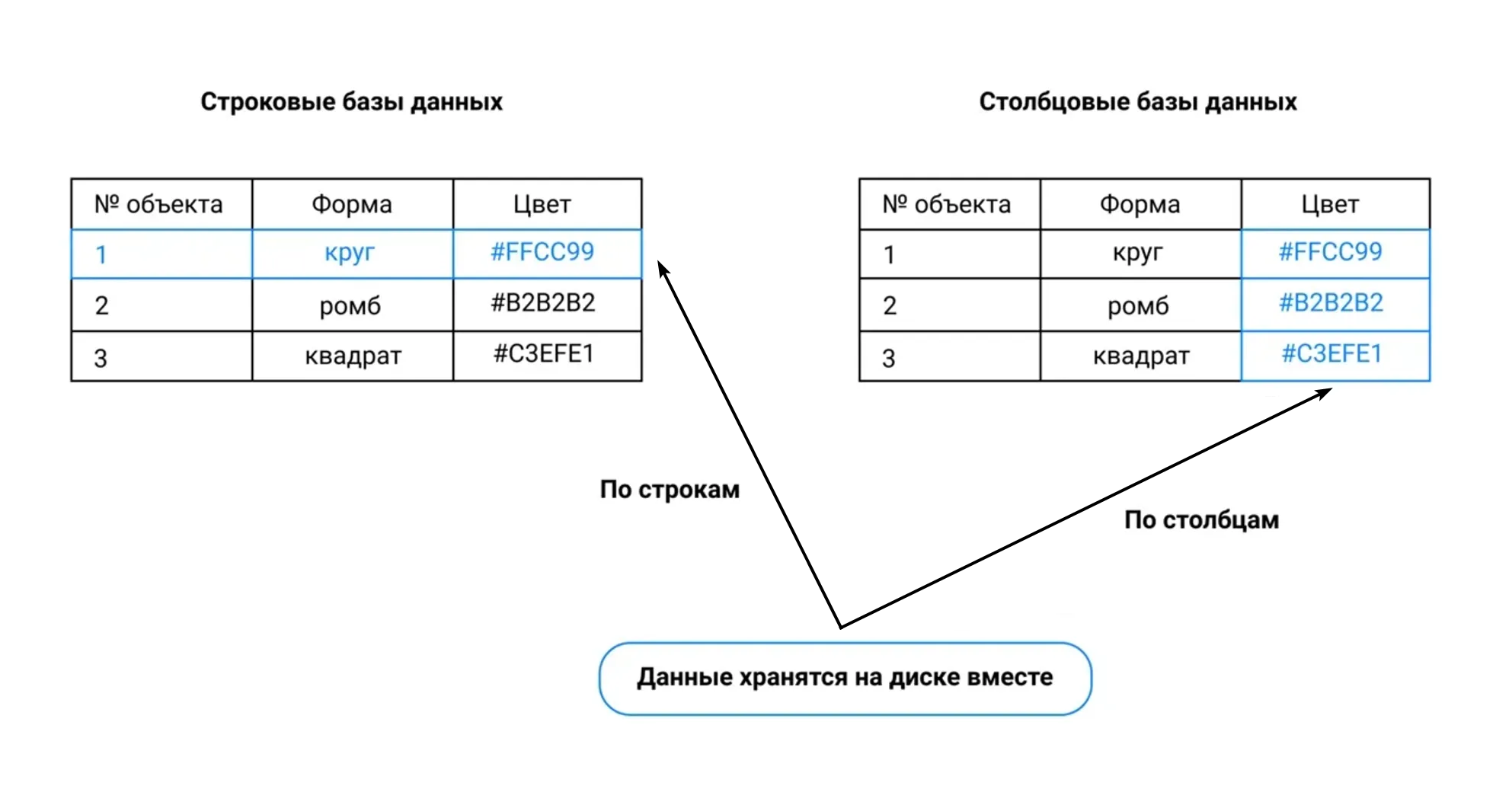
Благодаря такому способу хранения можно очень быстро выполнять запросы, в которых исследуются не все свойства объекта, а только некоторые из них. При поиске в строковых БД требуется просканировать всю таблицу, а строки читаются с диска или из памяти целиком, даже если из них нужно взять лишь одну ячейку. В столбцовых БД поиск идет по столбцам, извлекаются только нужные значения.
Выигрыш в скорости особенно заметен на больших объемах данных — СУБД ClickHouse способна читать сотни миллионов записей в секунду. БД горизонтально масштабируется, что позволяет работать с базой размером в несколько петабайт. Язык запросов в ней близок к стандартному SQL.
Ещё одна особенность ClickHouse: эта СУБД не поддерживает транзакции и точечное изменение или удаление записей (данные в базе изменяются и удаляются большими порциями).
Elasticsearch
Elasticsearch — это нереляционное хранилище данных с широким набором функций полнотекстового поиска.
Данные в Elasticsearch хранятся в виде документов в формате JSON. Они автоматически индексируются, размер индекса составляет от 20 до 30% размера БД. Благодаря этому достигается скорость чтения в сотни миллионов записей в секунду. Для взаимодействия с БД используются JSON-запросы в RESTful API, а в качестве языка запросов — Querydsl.
Elasticsearch хорошо масштабируется, что позволяет работать с большими объёмами данных. При этом она не обеспечивает транзакционную целостность, а запись данных в БД и их удаление не отличаются высокой производительностью.
Основное назначение Elasticsearch — полнотекстовый поиск в большом объёме документов. Эта СУБД широко применяется для аналитической обработки больших массивов данных, анализа логов и журналов работы приложений, функций автозавершения и умного ввода текста.
YDB
YDB — это разработанная Яндексом распределённая СУБД. Она относится к типу NewSQL: основана на реляционной модели, но обеспечивает отказоустойчивость, доступность и масштабируемость на уровне NoSQL-решений.
В YDB данные организуются в таблицы, обеспечивается их транзакционное изменение и строгая консистентность, запросы пишутся на диалекте SQL.
При этом YDB изначально разрабатывалась для так называемых OLTP-сценариев (On-Line Transaction Processing). Это задачи, где СУБД должна поддерживать транзакции и консистентность данных, как это делают классические реляционные СУБД, но при этом надёжно и быстро работать с объёмными БД (т. е. иметь возможность масштабироваться) и с большим числом одновременных запросов на чтение и на запись.
YDB может использоваться в двух режимах: режиме бессерверных вычислений и режиме с выделенными виртуальными машинами. Первый режим подходит для небольших систем с незначительной нагрузкой, когда держать виртуальные машины с БД невыгодно с финансовой точки зрения.
Apache Kafka
Apache Kafka — разработка компании LinkedIn, сочетание распределённой БД и очереди сообщений. Формально Apache Kafka определяется как распределённая стриминговая платформа, т. е. система, управляющая потоками данных между сервисами.
Дело в том, что серверные приложения часто состоят из множества сервисов. Одни из них генерируют, а другие получают данные. Важно, чтобы даже сотни тысяч сообщений в секунду передавались надёжно.
Для таких задач и используются очереди сообщений. Одни сервисы генерируют сообщения и отправляют их Apache Kafka, а другие считывают сообщения тогда, когда удобно, и тем самым снижают нагрузку на систему. До доставки сообщения хранятся в БД, которая размещается на нескольких хостах.
📂 YandexCloud | Последнее изменение: 15.08.2024 11:44