📂 Tooling
Ссылки
Курс DEV1
Postgres Professional - российская компания, разработчик систем управления базами данных https://postgrespro.ru/education/courses/DEV1
PostgreSQL driver for Python — Psycopg
Python adapter for PostgreSQL https://www.psycopg.org/
Коротко о PostgreSQL
Название: Postgres или PostgreSQL, но не “Postgre”.
Основные преимущества:
- Объектно-реляционная СУБД. Поддерживает объекты и классы, наследование, инкапсуляцию, полиморфизм.
- Поддержка множества типов данных (насчитал 43 типа в документации), в том числе JSON.
- Работа с большими объёмами.
- Поддержка сложных запросов.
- Написание функций на нескольких языках.
- Поддержка транзакционности – соответствие ACID, одновременная модификация базы (с использованием MVCC).
- Надёжность – резервирование и восстановление данных, репликация.
- Безопасность. Работа по защищенному SSL соединению, различные методы аутентификации.
- Производительность.
- Возможность расширения.
- Открытость.
- Кроссплатформенность.
PostgreSQL не имеет однозначных недостатков. Она подходит для проектов, где нужна мощная база данных с высокой функциональностью. Но для большинства приложений и сайтов требуется менее мощная и более быстрая, легковесная, простая в освоении СУБД. Обычно в таких случаях используется MySQL.
Всё же, выделим некоторые недостатки:
- Сложности при настройке, связанные с обилием возможностей и разнообразием функций.
- Повышенное потребление ресурсов, по сравнению с некоторыми другими СУБД.
Источники: Skillfactory | Скиллбокс
Транзакции
Четыре требования (”ACID”) к транзакциям:
- атомарность (atomicity): “всё или ничего”;
- согласованность (consistency): ограничения целостности и пользовательские ограничения; транзакция начинается в согласованном состоянии и, завершаясь, также сохраняет согласованность.
- изоляция (isolation): параллельно выполняющиеся транзакции не должны влиять друг на друга.
- долговечность (durability): сохранность данных даже после сбоя.
Управление транзакциями
В разных драйверах БД может быть по-разному: где-то включен autocommit после каждой операции по умолчанию, где-то commit надо делать явно.
Команды SQL:
BEGIN: начало транзакцииCOMMIT: зафиксировать все изменения в БД и завершить транзакцию.SAVEPOINT sp;: создать точку сохраненияROLLBACK TO sp;: отменить изменения в БД, выполненные после создания точки сохранения. При этом, транзакция продолжается.
Выполнение запроса
- Разбор: текст запроса разбирается парсером.
- Трансформация: запрос может преобразовываться по определенным правилам (например, виды заменяются на соответствующие им запросы).
- Планирование: специальный модуль СУБД составляет план выполнения запроса (как читать таблицу, использовать ли индексы, и т.п.).
- Выполнение запроса.
Подготовленные операторы
Для ускорения запроса, есть специальный режим, в котором сохраняются подготовленные операторы. То есть производится разбор, трансформация, и подготовленное дерево сохраняется, в дальнейшем нужна только подстановка параметров.
PREPARE: эта команда является расширением PostgreSQL, её нет в стандартном SQL.PREPARE q(integer) AS SELECT * FROM t WHERE id = $1;- выполнить разбор, трансформацию, сохранить полученное дерево разбора.EXECUTE q(1);- вызвать подготовленный оператор по имени с передачей параметра.SELECT * FROM pg_prepared_statements \gx: показать все подготовленные операторы. Ещё одно преимущество использования подготовленных операторов – невозможность внедрения SQL-кода.
Курсоры
Протокол позволяет открыть курсор для какого-либо оператора, а затем получать результирующие данные построчно по мере необходимости. Курсор должен использоваться в транзакциях.
BEGIN;
DECLARE c CURSOR FOR SELECT * FROM pg_tables;
FETCH c;Команда FETCН с; выдаёт очередную строку. Можно выбирать по несколько строк: FETCH 2 c;
Когда строки заканчиваются, FETCH просто перестаёт возвращать данные.
CLOSE c; закрывает курсор.
Также курсор закроется по завершении транзакции - COMMIT; .
Процессы и память
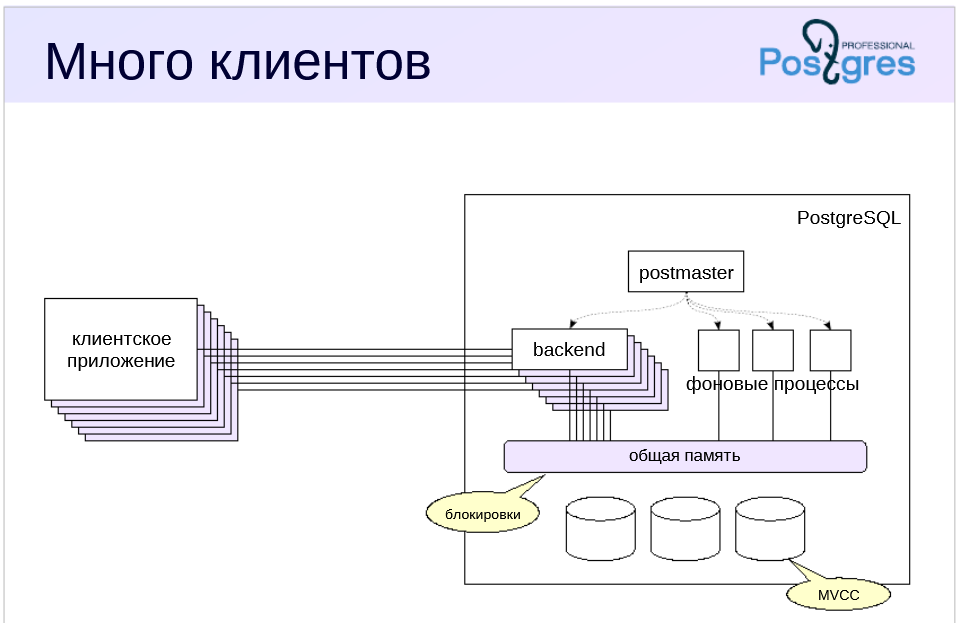
Для каждого клиента создаётся обслуживающий процесс (backend на схеме). В нём же хранятся подготовлнные операторы, курсоры, и т.п. конкретно для каждого клиента.
Для объектов в общей памяти используются короткоживущие блокировки. PostgreSQL делает это достаточно аккуратно для того, чтобы система хорошо масштабировалась при увеличении числа процессоров (ядер).
С таблицами сложнее, поскольку блокировки придется удерживать до конца транзакций (то есть потенциально в течение долгого времени), из-за чего масштабируемость может пострадать. Поэтому PostgreSQL использует механизм многоверсионности (MVCC, multiversion concurrency control) и изоляцию на основе снимков данных: одни и те же данные могут одновременно существовать в разных версиях, а каждый процесс видит собственную (но всегда согласованную) картину данных. Это позволяет блокировать только те процессы, которые пытаются изменить данные, уже измененные (но еще не зафиксированные) другими процессами.
Многоверсионность — тот основной механизм, который обеспечивает первые три свойства транзакций (атомарность, согласованность, изоляция).
Пул соединений
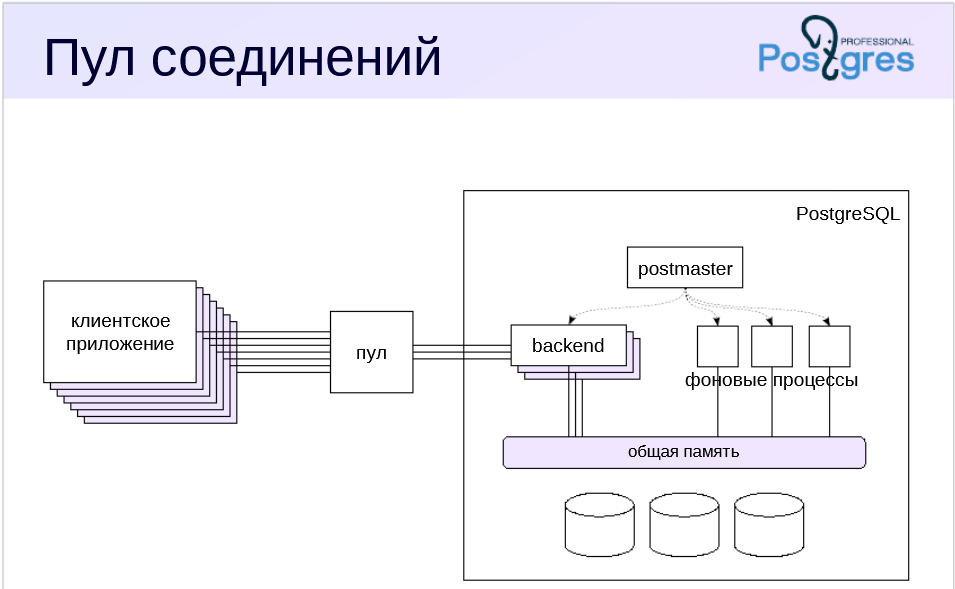
Если клиентов слишком много, или соединения устанавливаются и разрываются слишком часто, стоит подумать о применении пула соединений. Такую функцию обычно предоставляет сервер приложений, или можно воспользоваться сторонними менеджерами пула (наиболее известен PgBouncer).
Клиенты подключаются не к серверу PostgreSQL, а к менеджеру пула. Менеджер удерживает открытыми несколько соединений с сервером баз данных и использует одно из свободных для того, чтобы выполнять запросы клиента. Таким образом, с точки зрения сервера число клиентов остается постоянным вне зависимости от того, сколько клиентов обращаются к менеджеру пула.
Но при таком режиме работы несколько клиентов разделяют один и тот же обслуживающий процесс, который в своей локальной памяти хранит определенное состояние (в частности, разобранные запросы для подготовленных операторов). Это необходимо учитывать при разработке приложения.
Изоляция и многоверсионность
🔗 13.2. Изоляция транзакций | Глава 2 книги Рогова
Согласованность
Важная особенность реляционных СУБД — обеспечение согласованности (consistency), то есть корректности данных.
Известно, что на уровне базы данных можно создавать ограничения целостности (integrity constraints), такие как NOT NULL или UNIQUE. СУБД следит за тем, чтобы данные никогда не нарушали эти ограничения, то есть оставались целостными.
Если бы все ограничения были сформулированы на уровне базы данных, согласованность была бы гарантирована. Но некоторые условия слишком сложны для этого, например охватывают сразу несколько таблиц. Здесь помогают транзакции.
Транзакции, абсолютно правильные сами по себе, при одновременном выполнении могут начать работать некорректно. Это происходит из-за того, что перемешивается порядок выполнения операций разных транзакций. Если бы СУБД сначала выполняла все операции одной транзакции, а только потом — все операции другой, та- кой проблемы не возникало бы, но без распараллеливания работы производительность была бы невообразимо низкой.
Ситуации, когда корректные транзакции некорректно работают вместе, называются аномалиями одновременного выполнения.
Простой пример: если приложение хочет получить из базы согласованные данные, то оно как минимум не должно видеть изменения других незафиксированных транзакций. Иначе (если какая-либо транзакция будет отмене- на) можно увидеть состояние, в котором база данных никогда не находилась. Такая аномалия называется грязным чтением. Есть множество других, более сложных аномалий.
Роль СУБД состоит в том, чтобы выполнять транзакции параллельно и при этом гарантировать, что результат такого одновременного выполнения будет совпадать с результатом одного из возможных последовательных выполнений. Иными словами — изолировать транзакции друг от друга, устранив любые возможные аномалии.
Видимость версий строк
xmin, xmax - скрытые поля, содержат идентификатор той транзакции, которая создала эту версию.
CREATE TABLE t(s text);
INSERT INTO t VALUES ('First version');
BEGIN;
# Current transaction ID:
SELECT txid_current();
# Версии строки - пока одна:
SELECT *, xmin, xmax FROM t;
# (xmax = 0 значит, что строка актуальна).# В другом терминале запускаем новый сеанс psql
BEGIN;
# Номер транзакции будет другой:
SELECT txid_current();
# Запросим и увидим то же самое, что и в первом сеансе:
SELECT *, xmin, xmax FROM t;
# Меняем строку во втором сеансе
UPDATE t SET s = 'Second version';
# Запрашиваем заново, xmin увеличится, xmax будет также 0 (строка актуальна)
SELECT *, xmin, xmax FROM t;# Первый сеанс...
SELECT *, xmin, xmax FROM t;
# Увидим первую версию строки с xmax = версии со второго сеанса.# Второй сеанс...
COMMIT;# Первый сеанс...
SELECT *, xmin, xmax FROM t;
# Увидим новую версию строки с xmax = 0Блокировки

Если начата одна транзакция, которая делает например UPDATE строки в таблице, и параллельно начинается другая транзакция, которая делает UPDATE той же самой строки, второй UPDATE будет ждать, пока первая транзакция не завершится, и потом выполнится.

Для работы многоверсионности надо понимать, в каком статусе находятся транзакции. Транзакция может быть активна или завершена. Завершиться транзакция может либо фиксацией, либо обрывом. Таким образом, для представления состояния каждой транзакции требуются два бита. Статусы хранятся в специальных служебных файлах, а работа с ними происходит в общей памяти сервера, чтобы не приходилось постоянно обращаться к диску.
При любом завершении транзакции (как успешном, так и неуспешном) необходимо всего лишь установить соответствующие биты статуса. Как фиксация, так и обрыв транзакций происходят одинаково быстро.
Если прерванная транзакция успела создать новые версии строк, эти версии не уничтожаются (не происходит «физического» отката данных). Благодаря информации о статусах другие транзакции увидят, что транзакция, создавшая или удалившая версии строк, на самом деле прервана, и не станут принимать ее изменения во внимание.

Буферный кеш и журнал
Info
https://edu.postgrespro.ru/dev1-12/dev1_04_arch_wal_overview.html
DEV1-12. 04. Буферный кеш и журнал
Буферный кеш
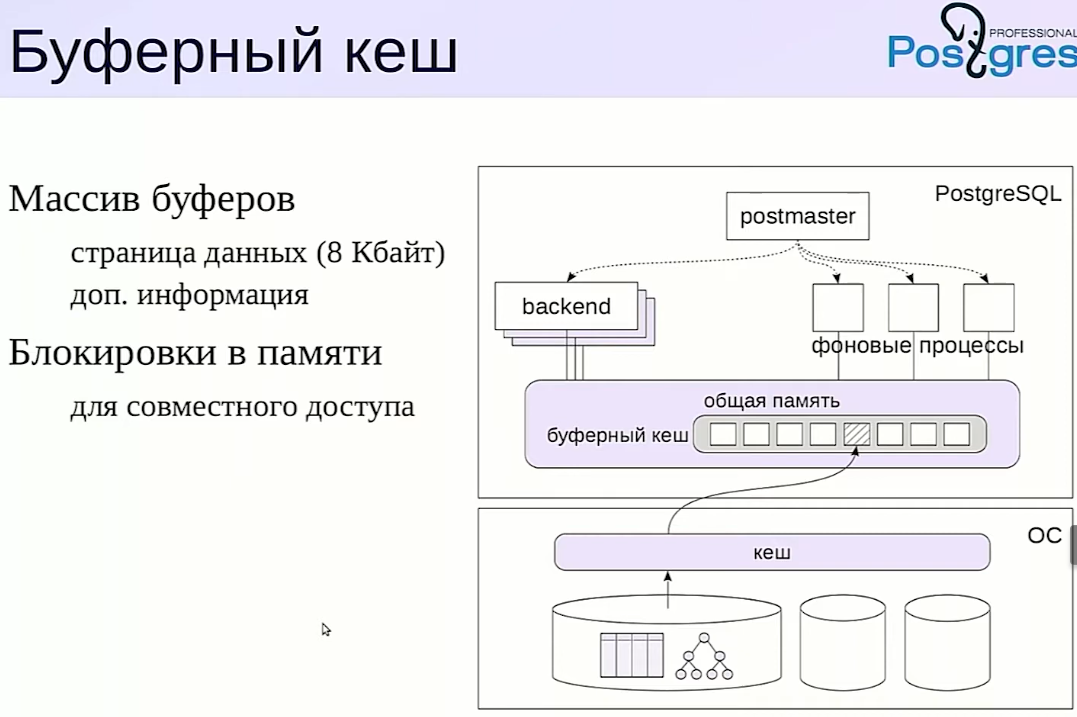
Буферный кеш используется для сглаживания скорости работы оперативной памяти и дисков. Он состоит из массива буферов, которые содержат страницы данных и дополнительную информацию (например, имя файла и положение страницы внутри этого файла).
Размер страницы обычно составляет 8 Кбайт (его можно изменить, но только при сборке PostgreSQL, и обычно в этом нет смысла). Любая работа со страницами данных проходит через буферный кеш. Если какой-либо процесс собирается работать со страницей, он
в первую очередь пытается найти ее в кеше. Если там страницы нет, процесс обращается к операционной системе с просьбой прочитать эту страницу и помещает ее в буферный кеш. (Обратите внимание, что ОС может прочитать страницу с диска, а может обнаружить ее в собственном кеше.)
После того, как страница записана в буферный кеш, к ней можно обращаться многократно без накладных расходов на вызовы ОС. Однако буферный кеш, как и другие структуры общей памяти, защищен блокировками для управления одновременным доступом. Хотя блокировки и реализованы эффективно, доступ к буферному кешу далеко не так быстр, как простое обращение к оперативной памяти. Поэтому в общем случае чем меньше данных читает и изменяет запрос, тем быстрее он будет работать.
Вытеснение
Алгоритм вытеснения выбирает в кеше страницу, которая в последнее время использовалась реже других, и заменяет ее новой. Если выбранная страница изменялась, то ее предварительно надо записать на диск, чтобы не потерять изменения (буфер, содержащий измененную страницу, называется «грязным»).
Такой алгоритм вытеснения называется LRU — Least Recently Used. Он сохраняет в кеше данные, с которыми происходит активная работа. Таких «горячих» данных обычно не так много, и при достаточном объеме буферного кеша получается существенно сократить количество обращений к ОС (и дисковых операций).
Пример
-
EXPLAIN (analyze, buffers, costs off, timing off)– вывести план после реального выполнения запроса, показан про буферы, и сколько это займёт времени. После этой команды делаем запрос, напримерSELECT * FROM t;.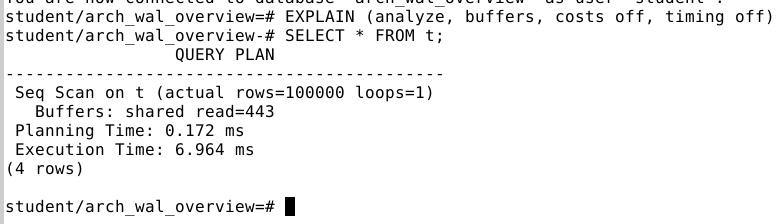
Запрос показывает, что 443 страницы прочитаны из диска в кэш.
-
Выполняем тот же самый запрос (
EXPLAIN … SELECT …;) ещё раз: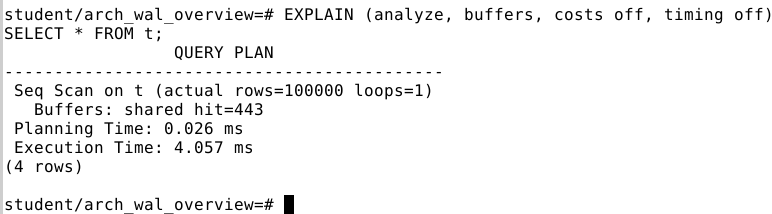
hit=443показывает, сколько страниц прочитаны из кэша. Время планирования и выполнения уменьшилось за счет использования кэша.https://postgrespro.ru/docs/postgresql/12/wal-intro
Журнал защищает все объекты, работа с которыми ведется в оперативной памяти: таблицы, индексы и другие объекты, статус транзакций.
Журнал WAL (Write-Ahead Log)
Для обеспечения надежности PostgreSQL использует журналирование. При выполнении любой операции формируется запись, содержащая минимально необходимую информацию для того, чтобы операцию можно было выполнить повторно. Такая запись должна попасть на диск (или другой энергонезависимый накопитель) раньше, чем будут
записаны изменяемые операцией данные (поэтому журнал и называется журналом предзаписи, write-ahead log).
SELECT * FROM pg_ls_waldir() ORDER BY name;выводит содержимое журнала.

Логическая структура данных
Info
https://edu.postgrespro.ru/dev1-12/dev1_05_data_logical.html
DEV1-12. 05. Логическая структура данных
DEV1-12.
https://www.youtube.com/watch?v=cOjAk1g0stE
Логическая структура:
- кластер содержит базы данных
- базы данных содержат схемы
- схемы содержать конкретные объекты (таблицы, индексы и т.п.).
Базы данных и шаблоны
Экземпляр PostgreSQL управляет несколькими базами данных — кластером. При инициализации кластера (автоматически при установке PostgreSQL либо вручную командой initdb) создаются три одинаковые базы данных (postgres, template1, template0). Все остальные БД, создаваемые пользователем, клонируются из какой-либо существующей.
Шаблонная БД template1 используется по умолчанию для создания новых баз данных. В нее можно добавить объекты и расширения, которые будут копироваться в каждую новую базу данных.
Шаблон template0 не должен изменяться. Он нужен как минимум в двух ситуациях. Во-первых, для восстановления БД из резервной копии, выполненной утилитой pg_dump. Во-вторых, при создании новой БД с кодировкой, отличной от указанной при инициализации кластера.
База данных postgres используется при подключении по умолчанию пользователем postgres. Она не является обязательной, но некоторые утилиты предполагают ее наличие, поэтому ее не рекомендуется удалять, даже если она не нужна.
https://postgrespro.ru/docs/postgresql/12/manage-ag-templatedbs
Схемы
Схемы представляют собой пространства имен для объектов БД. Они позволяют разделить объекты на логические группы для управления ими, предотвратить конфликты имен при работе нескольких пользователей или приложений.
В PostgreSQL схема и пользователь — разные сущности (хотя настройки по умолчанию упрощают работу с одноименными схемами). Существует несколько специальных схем, обычно присутствующих в каждой базе данных.
Схема public используется по умолчанию для хранения объектов, если не выполнены иные настройки.
Схема pg_catalog хранит объекты системного каталога. Системный каталог — это метаинформация об объектах, принадлежащих кластеру, которая хранится в самом кластере в виде таблиц. Альтернативное представление системного каталога (определенное в стандарте SQL) дает схема information_schema.
Схема pg_temp служит для хранения временных таблиц. (На самом деле таблицы создаются в схемах pg_temp_1, pg_temp_2 и т. п. — у каждого пользователя своя схема. Но обращаются все пользователи к ней как к pg_temp.)
Есть и другие схемы, но они носят технический характер. https://postgrespro.ru/docs/postgresql/12/ddl-schemas
В psql есть команда для вывода схем - \dn .
CREATE SCHEMA special; создаёт новую схему.
ALTER TABLE t SET SCHEMA special; ”перенесёт” таблицу в указанную схему.
SELECT * FROM special.t; запрашивает данные из таблицы в конкретной схеме.
DROP SCHEMA special; удаляет схему.
Системный каталог
Системный каталог хранит метаинформацию об объектах кластера. В каждой базе данных имеется собственный набор таблиц, описывающих объекты этой конкретной базы. Также есть несколько таблиц, общих для всего кластера и не принадлежащих никакой отдельной БД. Для удобства над таблицами также определены несколько представлений. https://postgrespro.ru/docs/postgresql/12/catalogs
К системному каталогу можно обращаться с помощью обычных запросов SQL, а psql имеет целый ряд команд для удобства просмотра. Таблицы системного каталога не обновляют напрямую; они изменяются автоматически при выполнении команд DDL.
https://postgrespro.ru/docs/postgresql/12/app-psql
Все имена таблиц системного каталога начинаются с pg_, например, pg_database. Столбцы таблиц начинаются с префикса, обычно соответствующего имени таблицы, например, datname. Имена объектов хранятся в нижнем регистре, например, 'postgres'. В таблицах системного каталога первичные ключи не определены явным образом, но в большинстве случаев в качестве первичного ключа выступает столбец oid, имеющий специальный тип oid — object identifier (целое 32-битное число). До версии PostgreSQL 12 этот столбец был скрытым (его можно было увидеть, только явно указав имя в списке SELECT). https://postgrespro.ru/docs/postgresql/12/datatype-oid
Команды psql, такие как например \l, фактические выполняют запросы к системному каталогу. Чтобы увидеть эти запросы, нужно сделать set ECHO_HIDDEN on.
Физическая структура данных
Info
https://edu.postgrespro.ru/dev1-12/dev1_06_data_physical.html
DEV1-12. 06. Физическая структура данных
Табличные пространства
Табличные пространства (ТП) служат для организации физического хранения данных и определяют расположение данных в файловой системе.
Например, можно создать одно табличное пространство на медленных дисках для архивных данных, а другое – на быстрых дисках для данных, с которыми идет активная работа.
При инициализации кластера создаются два табличных пространства: pg_default и pg_global.
Одно и то же табличное пространство может использоваться разными базами данных, а одна база данных может хранить данные в нескольких табличных пространствах.
При этом у каждой БД есть так называемое «табличное пространство по умолчанию», в котором создаются все объекты, если явно не указать иное. В этом же табличном пространстве хранятся и объекты системного каталога. Изначально в качестве «табличного пространства по умолчанию» используется pg_default, но можно установить и другое.
Табличное пространство pg_global особенное: в нем хранятся те объекты системного каталога, которые являются общими для кластера.
Чтобы просмотреть табличные пространства:
\dbвpsqlSELECT spcname FROM pg_tablespace;
Каталоги
Стандартные табличные пространства pg_global и pg_default всегда находятся в PGDATA/global/ и PGDATA/base/ соответственно.
При создании пользовательского табличного пространства указывается произвольный каталог. Сервер всегда использует относительные пути, поэтому на указанный каталог дополнительно создается символьная ссылка в каталоге PGDATA/pg_tblspc/.
Внутри каталога PGDATA/base/ данные дополнительно разложены по подкаталогам баз данных (для PGDATA.global/ это не требуется, так как данные в нем относятся к кластеру в целом).
Внутри каталога пользовательского табличного пространства появляется еще один уровень вложенности: подкаталог для версии сервера PostgreSQL. Это сделано для удобства обновления сервера на другую версию.
Сами объекты хранятся в файлах внутри этих каталогов. У каждого объекта собственный набор файлов: в одном файле находятся данные только одного объекта.
Каждый файл, называемый сегментом, занимает по умолчанию не более 1 Гбайт (этот размер можно изменить при сборке сервера). Поэтому каждому объекту может соответствовать несколько файлов. Необходимо учитывать влияние потенциально большого количества файлов на используемую файловую систему.
https://postgrespro.ru/docs/postgresql/12/storage-file-layout
Пример создания tablespace
- Создаём директорию:
sudo -u postgres mkdir /var/lib/postgresql/ts_dir. Необходимо сделать это от имени пользователяpostgres. CREATE TABLESPACE ts LOCATION '/var/lib/postgresql/ts_dir';\dbпокажет наличие и расположение нового табличного пространства.CREATE DATABASE data_physical TABLESPACE ts;создадим БД в новом табличном пространстве.
Слои (forks) и файлы
Обычно каждому объекту соответствует несколько слоев (forks). Каждый слой — это набор сегментов (то есть файл или несколько файлов). Все файлы-сегменты разбиты на отдельные страницы, обычно по 8 Кбайт (размер можно установить для всего кластера только при сборке сервера). Страницы разных объектов считываются с диска совершенно однотипно через общий механизм буферного кеша.
Основной слой — это собственно данные: версии строк таблиц или строки индексов.
Слой vm (visibility map) — битовая карта видимости. В ней отмечены страницы, которые содержат только актуальные версии строк, видимые во всех снимках данных. Иными словами, это страницы, которые давно не изменялись и успели полностью очиститься от неактуальных версий.
Карта видимости применяется для оптимизации очистки (отмеченные страницы не нуждаются в очистке) и для ускорения индексного доступа. Дело в том, что информация о версионности хранится только для таблиц, но не для индексов (поэтому у индексов не бывает карты видимости). Получив из индекса ссылку на версию строки, нужно прочитать табличную страницу, чтобы проверить ее видимость. Но если в самом индексе уже есть все нужные столбцы, и при этом страница отмечена в карте видимости, то к таблице можно не обращаться.
Слой fsm (free space map) — карта свободного пространства. В ней отмечено доступное место внутри страниц, образующееся при очистке. Эта карта используется при вставке новых версий строк, чтобы быстро найти подходящую страницу.
SELECT pg_relation_filepath('t'); - посмотреть файлы, относящиеся к таблице t.
ALTER TABLE t SET TABLESPACE pg_default; - перенести таблицу в другое табличное пространство. Приводит к физическому переносу файлов.
SELECT pg_database_size('data_physical'); - выводит размер БД в байтах.
SELECT pg_size_pretty(pg_database_size('data_physical')); - то же самое вывести в Мб.
SELECT pg_size_pretty(pg_total_relation_size('t')); - размер таблицы вместе со всеми индексами.
SELECT pg_size_pretty(pg_table_size('t')); - размер чисто таблицы.
SELECT pg_size_pretty(pg_indexes_size('t')); - размер чисто индексов.
TOAST
Любая версия строки в PostgreSQL должна целиком помещаться на одну страницу. Для «длинных» версий строк применяется технология TOAST — The Oversized Attributes Storage Technique. Она подразумевает несколько стратегий. Подходящий «длинный» атрибут может быть сжат так, чтобы версия строки поместилась на страницу. Если это не получается, атрибут может быть отправлен в отдельную служебную таблицу. Могут применяться и оба подхода.
Для каждой основной таблицы при необходимости создается отдельная toast-таблица (и к ней специальный индекс). Такие таблицы и индексы располагаются в отдельной схеме pg_toast и поэтому обычно не видны.
Версии строк в toast-таблице тоже должны помещаться на одну страницу, поэтому «длинные» значения хранятся порезанными на части. Из этих частей PostgreSQL прозрачно для приложения «склеивает» необходимое значение.
Toast-таблица используется только при обращении к «длинному» значению. Кроме того, для toast-таблицы поддерживается своя версионность: если обновление данных не затрагивает «длинное» значение, новая версия строки будет ссылаться на то же самое значение в toast-таблице. Это позволяет экономить место. https://postgrespro.ru/docs/postgresql/12/storage-toast
Проектирование структуры данных в БД
Info
https://edu.postgrespro.ru/dev1-12/dev1_07_bstore_schema.html
DEV1-12. 07. Схема данных приложения «Книжный магазин»
DEV1-12.
https://www.youtube.com/watch?v=waQ_04sbP98
ER-модель (entity relationship): выделяются основные сущности предметной области, устанавливаются связи (отношения) между ними, определяются атрибуты (свойства сущностей и связей). EAV-модель (enriry - attribute - value): таблица из трёх перечисленных колонок, в которую можно запихать всё, что угодно. Нормализация - уменьшение избыточности данных, разбиение сущностей на более мелкие.На такой схеме: одна палочка - “один”, три палочки в виде лапки - “многие”.
Структура данных книжного приложения
CREATE SCHEMA bookstore;
ALTER DATABASE bookstore SET search_path = bookstore, public;
# \c bookstore
SHOW search_path;
CREATE TABLE authors(
author_id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
last_name text NOT NULL,
first_name text NOT NULL,
middle_name text
);
CREATE TABLE books(
book_id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
title text NOT NULL
);
CREATE TABLE authorship(
book_id integer REFERENCES books,
author_id integer REFERENCES authors,
seq_num integer NOT NULL,
PRIMARY KEY (book_id,author_id)
);
CREATE TABLE operations(
operation_id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
book_id integer NOT NULL REFERENCES books,
qty_change integer NOT NULL,
date_created date NOT NULL DEFAULT current_date
);Функции
Info
https://edu.postgrespro.ru/dev1-12/dev1_08_sql_func.html
Функции всегда вызываются в контексте какого-то выражения. В функциях нельзя управлять транзакциями. Функции являются такими же объектами базы данных, как, например, таблицы и индексы. Определение функции сохраняется в системном каталоге; поэтому функции в базе данных называют хранимыми.
CREATE FUNCTION hello_world()
RETURNS text
AS $$ SELECT 'Hello, world!'; $$
LANGUAGE sql;
# Вызов
SELECT hello_world();
# With param -------------------------------------------------------------
CREATE FUNCTION hello(name text)
RETURNS text
AS $$ SELECT 'Hello, ' || name || '!'; $$
LANGUAGE sql;
# Call
SELECT hello('Alex');
# Delete function --------------------------------------------------------
DROP FUNCTION hello(text); # param name can be omitted
# With multiple params ---------------------------------------------------
# `IN` means `input parameter`
CREATE FUNCTION hello(IN name text, IN title text DEFAULT 'Mr')
RETURNS text
AS $$ SELECT 'Hello, ' || title || ' ' || name || '!'; $$
LANGUAGE sql;
# Call
SELECT hello('Alex', 'Mr');
SELECT hello('Alex'); # parameter with DEFAULT can be omitted
SELECT hello(title => 'Mr', name => 'Alex');
# Function with multiple output params ------------------------------------
# This will return text and time.
CREATE FUNCTION hello(IN name text, OUT greeting text, OUT clock timetz)
AS $$ SELECT 'Hello, ' || name || '!', current_time; $$
LANGUAGE sql;Категории изменчивости
Каждой функции сопоставлена категория изменчивости, которая определяет свойства возвращаемого значения при одинаковых значениях входных параметров.
Категория volatile говорит о том, что возвращаемое значение может произвольно меняться. Такие функции будут вычисляться при каждом вызове. Если при создании функции категория не указана, назначается именно эта категория.
Категория stable используется для функций, возвращаемое значение которых не меняется в пределах одного SQL-оператора. В частности, такие функции не могут менять состояние БД. Такая функция может быть выполнена один раз во время выполнения запроса, а затем будет использоваться вычисленное значение.
Категория immutable еще более строгая: возвращаемое значение не меняется никогда. Такую функцию можно вычислить на этапе планирования запроса, а не во время выполнения.
Можно — не означает, что всегда происходит именно так, но планировщик вправе выполнить такие оптимизации. В некоторых (простых) случаях планировщик делает собственные выводы об изменчивости функции, невзирая на указанную явно категорию. https://postgrespro.ru/docs/postgresql/12/xfunc-volatility
Процедуры
DEV1-12. 09. Процедуры
Info
https://edu.postgrespro.ru/dev1-12/dev1_09_sql_proc.html
В отличие от функций, которые всегда вызываются в контексте какого-либо выражения, процедуры вызываются самостоятельно операторомCALL. Процедуры могут управлять транзакциями (но только не на языке SQL!).
# Define
CREATE PROCEDURE fill()
AS $$
TRUNCATE t;
INSERT INTO t SELECT random() FROM generate_series(1,3);
$$ LANGUAGE sql;
# Call
CALL fill();
# With param
CREATE PROCEDURE fill(nrows integer)
AS $$
TRUNCATE t;
INSERT INTO t SELECT random() FROM generate_series(1,nrows);
$$ LANGUAGE sql;
# Call with param
CALL fill(nrows => 5);Перегрузка
Перегрузка — это возможность использования одного и того же имени для нескольких подпрограмм (функций или процедур), отличающихся типами параметров IN и INOUT. Иными словами, сигнатура подпрограммы — ее имя и типы входных параметров.
Полиморфизм
В некоторых случаях удобно не создавать несколько перегруженных подпрограмм для разных типов, а написать одну, принимающую параметры любого (или почти любого) типа.
Для этого в качестве типа формального параметра указывается специальный полиморфный псевдотип. Пока мы ограничимся одним типом — anyelement, который соответствует любому базовому типу, — но позже познакомимся и с другими.
Конкретный тип, с которым будет работать подпрограмма, выбирается во время выполнения по типу фактического параметра.
Составные типы данных
DEV1-12. 10. Составные типы
Info
Составной тип — это набор атрибутов, каждый из которых имеет свое имя и свой тип. Составной тип можно рассматривать как табличную строку. Часто он называется «записью» (а в Си-подобных языках такой тип называется «структурой»).
Составной тип — объект базы данных, его объявление регистрирует новый тип в системном каталоге, после чего он становится полноценным типом SQL. При создании таблицы автоматически создается и одноименный составной тип, представляющий строку этой таблицы. Важное отличие состоит в том, что в составном типе нет ограничений целостности.
Атрибуты составного типа могут использоваться как обычные скалярные значения (хотя атрибут, в свою очередь, тоже может иметь составной тип).
Составной тип можно использовать как любой другой тип SQL, например, создавать столбцы таблиц этого типа и т.п. Значения составного типа можно сравнивать между собой, проверять на неопределенность (NULL), использовать с подзапросами в таких конструкциях, как IN, ANY/SOME, ALL.
Явное объявление составного типа
CREATE TYPE currency AS (
amount NUMERIC,
code TEXT
);Посмотреть типы в psql можно командой \dT.
С созданным типом можно работать как с любым другим типом SQL:
CREATE TABLE transactions(
account_id INTEGER,
debit currency,
creadit currency,
date_created DATE DEFAULT current_date
);Конструирование значений составных типов
Значение составного типа формируется в виде строки, внутри которой в скобках перечислены значения. Строковые значения заключаются в двойные кавычки.
INSERT INTO transactions VALUES (1, NULL, '(100.00, "RUR")');Другой способ – использовать табличный конструктор ROW:
INSERT INTO transactions VALUES (2, ROW(80.00, 'RUR'), NULL);Атрибуты составного типа как скалярные значения
SELECT (t.debit).amount, (t.credit).amount FROM transactions t;Использование составных типов с подзапросами
SELECT * FROM seats WHERE (line, number) IN (
SELECT line, number FROM tickets WHERE movie_start = current_date
);Использование составных типов как параметров функции
- функция соединяет номер ряда и места и возвращает как строку
- seats ниже это пользовательский тип
CREATE FUNCTION seat_no(seat seats) RETURNS text
AS $$
SELECT seat.line || seat.number;
$$ IMMUTABLE LANGUAGE sql;Функции, возвращающие множество строк (табличные функции)
Напишем функцию, которая вернет все места в прямоугольном зале заданного размера, типа seats.
CREATE FUNCTION rect_hall(max_line INTEGER, max_number INTEGER)
RETURNS SETOF seats
AS $$
SELECT chr(line+64), number
FROM generate_series(1, max_line) AS lines(line),
generate_series(1, max_number) AS numbers(number);
$$ IMMUTABLE LANGUAGE sql;
SELECT * FROM rect_hall(max_line => 2, max_number => 3);Часть курса про язык PL/pgSQL – PLpgSQL.
Обзор разграничения доступа
Роли и атрибуты
Роль – это пользователь СУБД. Не связана с пользователем ОС.
При создании новых ролей нужно позаботиться о возможности их подключения к серверу.
Свойства роли определяются атрибутами:
LOGIN: возможность подключенияSUPERUSER: суперпользователь (имеет доступ ко всем объектам системы)CREATEDB: возможность создавать БДCREATEROL: возможность создавать ролиREPLICATION: использование протокола репликации- …и другие.
Могут быть “обратные” атрибуты приставкой NO, например NOLOGIN, которые запрещают соответствующее действие.
Привилегии
Привилегии определяют права доступа ролей к объектам.
Политики защиты строк
Дополнение к системе привилегий для разграничения доступа к таблицам на уровне строк.
Защита включается явно для каждой таблицы:
- не действует на владельца, суперпользователей и роли с атрибутом
BYPASSRLS - не действует на ограничения целостности.
Логическое резервирование
Логическая копия
Логическая копия – это набор команд SQL для создания объектов БД и наполнения данными.
Достоинства:
- можно сделать копию отдельного объекта или целой базы
- можно восстановиться на другой версии или архитектуре (не требуется двоичная совместимость)
- простота использования
Недостатки:
- невысокая скорость работы
- восстановление только на момент создания резервной копии
Физическая копия
Физическая копия представляет собой копию файловой системы кластера баз данных.
Достоинства:
- быстрее, чем логическое резервирование
- восстанавливается статистика
Недостатки:
- можно восстановиться только на совместимой системе и на той же самой основной версии PostgreSQL
- выборочная копия невозможна, копируется весь кластер
Если ведется архив журнала предзаписи, то существует возможность восстановления на определенный момент времени.
Физическое копирование является основным иструментом для резервного копирования БД.
Копия таблицы в SQL
COPY table TO 'file';
COPY table TO stdout WITH (format csv);
COPY table FROM 'file';Файл в файловой системе сервера и доступен владельцу экземпляра PostgreSQL. Можно ограничить столбцы (или использовать произвольный запрос). При восстановлении строки добавляются к имеющимся в таблице.
Копия таблицы в psql
\copy table to 'file'
\copy table from 'file'
Копирует просто данные, разделенные табуляцией, без команд SQL. Можно гибко настраивать параметры вывода.
Файл в файловой системе клиента и доступен пользователю ОС, запустившему psql. Происходит пересылка данных между клиентом и сервером. Синтаксис и возможности аналогичны команде COPY.
Копия базы данных
pg_dump -d db_name -f filename
# Восстановить:
psql -f filenameФормат: команды SQL.
При выгрузке можно выбрать отдельные объекты БД.
База, в которую будет восстанавливаться из файла, нужно создать из шаблона template0, иначе могут возникнуть нестыковки.
Заранее должны быть созданы роли и табличные пространста.
После загрузки имеет смысл выполнить ANALYZE.
pg_dump -d db_name -F c -f filename
# Восстановить:
pg_restore -d db_name -j N filenameФормат: внутренний с оглавлением.
Отдельные элементы базы данных можно выбрать на этапе восстановления.
Возможна загрузка в несколько параллельных потоков N.
pg_dump -d db_name -F d -j N -f directory
# Восстановить:
pg_restore -d db_name -j N directoryКаталог с оглавлением и отдельными файлами на каждый объект БД.
Отдельные элементы базы данных можно выбрать на этапе восстановления.
Возможна выгрузка и загрузка в несколько параллельных потоков N.
Примеры в видео, как всем этим пользоваться
📂 Tooling | Последнее изменение: 14.05.2024 20:37